random【擬似乱数】3.2 / 3.6 / 3.9~3.113.12
メモ ( 概要 状態関数 例 ランダム値生成関数 例 シーケンス操作関数 例 実数値分布関数 例 クラス・関数 ) 例
メモ
- 概要
- シミュレーション等の用途で扱う乱数
- パスワード等の機密情報を扱う場合は、secrets【暗号論的擬似乱数】を利用
- 外部ライブラリの NumPy【科学技術計算】等にも存在するので、状況に合わせて使い分け
- 状態関数〔 例 〕
seed【初期化】3.2 / 3.9 / 3.11 getstate【内部状態取得】 setstate【内部状態設定】 - ランダム値生成関数〔 例 〕
getrandbits【ランダム整数生成 (ビット指定)】 randbytes【ランダムバイト生成】3.9 randint【ランダム整数生成】 3.2 randrange【ランダム整数生成 (等差数列)】 3.2 / 3.103.12 - シーケンス操作関数〔 例 〕
choice【要素選択】 3.2 choices【複数要素選択 (重複あり)】3.6 shuffle【シャッフル (インプレース)】 3.2 / 3.9 / 3.11 sample【複数要素選択 (重複なし)】 3.2 / 3.9 - 離散分布関数
binomialvariate【二項分布】3.12 - 実数値分布関数〔 例 〕
- クラス・関数
クラス 備考 class random.Random( [seed] ) 擬似乱数 (デフォルト)
seedシード値
None | int | float | str | bytes | bytearray
その他 3.9class random.SystemRandom( [seed] ) システム提供乱数 (secrets【暗号論的擬似乱数】 参照)
seedシード値 (無視)
NotImplementedError 例外 getstate【内部状態取得】・setstate【内部状態設定】呼び出し関数 備考 betavariate(alpha, beta) ベータ分布
戻り値ベータ分布の乱数
alpha形状α (0<alpha)
beta形状β (0<beta)binomialvariate(n=1, p=0.5) 3.12 二項分布
成功数 (整数:0~n)
n試行回数 (負でない整数)
p成功確率 (0.0 ≦ p ≦ 1.0)choice(seq) 3.2 要素選択
戻り値seq内の1つ
seq空でないシーケンス
IndexError 例外seqが空
※生成改善 3.2choices(
population,
weights=None,
*,
cum_weights=None,
k=1) 3.6複数要素選択 (重複あり)
戻り値選択要素
population母集団のシーケンス
weights相対的な重みのシーケンス (非負数 / 内部で累積的な重みに変換)
cum_weights (キーワード引数)累積的な重みのシーケンス (非負数)
k (キーワード引数)選択数
IndexError 例外populationが空
TypeError 例外weights と cum_weights を両方指定
ValueError 例外3.9 重みが全て0 / 重みの数がpopulationの数と相違expovariate(lambd=1.0) 3.12 指数分布
戻り値指数分布の乱数
lambd平均にしたい値の逆数 (デフォルト:1.0 3.12 )gammavariate(alpha, beta) ガンマ分布
戻り値ガンマ分布の乱数
alpha形状母数 (0<)
beta尺度母数 (0<)gauss(mu=0.0, sigma=1.0) ガウス分布
戻り値ガウス分布の乱数
mu平均 (デフォルト:0.03.11 )
sigma標準偏差 (デフォルト:1.03.11 )
※normalvariate【正規分布】より少し高速、但しスレッドセーフではないgetrandbits(k) ランダム整数生成 (ビット指定)
戻り値ランダム整数 (kビット)
kビット数 (0 も可3.9 )getstate() 内部状態取得
戻り値内部状態オブジェクトlognormvariate(mu, sigma) 対数正規分布
戻り値対数正規分布の乱数
mu平均
sigma標準偏差 (0<)normalvariate(mu=0.0, sigma=1.0) 正規分布
戻り値正規分布の乱数
mu平均 (デフォルト:0.03.11 )
sigma標準偏差 (デフォルト:1.03.11 )
※gauss【ガウス分布】paretovariate(alpha) パレート分布
戻り値パレート分布の乱数
alpha形状randbytes(n) 3.9 ランダムバイト生成
戻り値ランダムバイト
nバイト数randint(a, b) 3.2 ランダム整数生成
戻り値ランダム整数N (a≦N≦b)
a下限 (含む)
b上限 (含む)
※生成改善 3.2random() 一様分布
戻り値一様分布の乱数N (0.0≦N<1.0)randrange(start, stop[, step]) 3.23.12
randrange(stop) 3.23.12ランダム整数生成 (等差数列)
戻り値ランダム整数N (start≦N<stop)
start開始整数値 (省略:0)
stop終了整数値 (含まない)
stepステップ整数値 (省略:1)整数と同等の非整数は整数に自動変換 (例:10.0) 3.10上記以外の非整数はValueErrorTypeError 例外3.10
非整数の自動変換なし (非整数:TypeError 例外) 3.12
※choice(range(start, stop, step)) と同等
※生成改善 3.2sample(
population,
k,
*,
counts3.9 =None)複数要素選択 (重複なし)
戻り値選択要素
population母集団のシーケンス (set【集合型 (可変)】3.9 不可3.11 )
k選択数
counts (キーワード引数)3.9複製数のシーケンス
ValueError 例外populationの大きさ<k
※生成改善 3.2seed(a=None, version3.2 =2) 初期化
aシード値 (省略:現在システム時刻)
NoneType | int | float | str | bytes | bytearray
その他 3.9エラー3.11
version3.2バージョン (省略:2)setstate(state) 内部状態設定
state内部状態オブジェクトshuffle(x [, random3.9]3.11 )シャッフル (インプレース)
xシーケンスrandom3.90.0 以上 1.0 未満の数値を返却する関数 (デフォルト:random【一様分布】)3.11
※生成改善 3.2triangular(low=0.0, high=1.0, mode=None) 三角分布
戻り値三角分布の乱数
low最小値
high最大値
mode最頻値 (省略:lowとhighの中間)uniform(a, b) 一様分布 (範囲指定)
戻り値 一様分布の乱数N (a≦N≦b または b≦N≦a)
a最小値 (最大値)
b最大値 (最小値)vonmisesvariate(mu, kappa) フォン・ミーゼス分布
戻り値フォン・ミーゼス分布の乱数
mu平均の角度 (ラジアン単位:0 ~ 2π)
kappa濃度 (0≦)weibullvariate(alpha, beta) ワイブル分布
戻り値ワイブル分布の乱数
alpha尺度
beta形状
外部リンク
例
状態関数
import random
# seed(a=None, version=2)【初期化】
for i in range(5):
print(random.randint(0, 10))
# 出力例:
# 7
# 3
# 4
# 4
# 9
random.seed(1234567)
rnd_1 = [random.randint(0, 10) for i in range(5)]
random.seed(1234567)
rnd_2 = [random.randint(0, 10) for i in range(5)]
for i in range(5):
print(rnd_1[i], rnd_2[i], (rnd_1[i] == rnd_2[i]))
# 出力例:
# 6 6 True
# 3 3 True
# 1 1 True
# 9 9 True
# 5 5 True
# getstate()【内部状態取得】
random.seed()
for i in range(5):
print(random.randint(0, 10))
# 出力例:
# 6
# 2
# 10
# 5
# 7
state = random.getstate()
rnd_3 = [random.randint(0, 10) for i in range(5)]
# setstate(state)【内部状態設定】
for i in range(5):
print(random.randint(0, 10))
# 出力例:
# 1
# 5
# 4
# 9
# 10
random.setstate(state)
rnd_4 = [random.randint(0, 10) for i in range(5)]
for i in range(5):
print(rnd_3[i], rnd_4[i], (rnd_3[i] == rnd_4[i]))
# 出力例:
# 7 7 True
# 6 6 True
# 0 0 True
# 1 1 True
# 4 4 True
ランダム値生成関数
import random
# getrandbits(k)【ランダム整数生成 (ビット指定)】
for i in range(5):
k = (i + 1) * 8
rnd = random.getrandbits(k)
print(f'({k}) {rnd:#012x} {rnd:#051_b}')
# 出力例:
# (8) 0x0000000075 0b0000_0000_0000_0000_0000_0000_0000_0000_0111_0101
# (16) 0x000000ee40 0b0000_0000_0000_0000_0000_0000_1110_1110_0100_0000
# (24) 0x00002a3226 0b0000_0000_0000_0000_0010_1010_0011_0010_0010_0110
# (32) 0x00945bbef7 0b0000_0000_1001_0100_0101_1011_1011_1110_1111_0111
# (40) 0x159744dc3c 0b0001_0101_1001_0111_0100_0100_1101_1100_0011_1100
# randbytes(n)【ランダムバイト生成】
for i in range(5):
bytes = random.randbytes(10)
print(bytes)
# 出力例:
# b'?\xba&x\xbf\x9a\\\x8fSG'
# b'\xeaj\xec\x112D\xfdX2G'
# b'7V\xbf\xe6Ev\xcf\x9e\x19\x00'
# b'{\x87\x87\xb5!2{M\xf3\xe9'
# b'\x96\x98i\x8eL \xc3\xfc\xa5\x90'
# randint(a, b)【ランダム整数生成】
for i in range(5):
rnd = random.randint(10, 20)
print(rnd)
# 出力例:
# 11
# 10
# 12
# 20
# 16
# randrange(start, stop[, step])【ランダム整数生成 (等差数列)】
for i in range(5):
rnd = random.randrange(3, 33, 3)
print(rnd)
# 出力例:
# 12
# 9
# 6
# 30
# 3
# randrange(stop)【ランダム整数生成 (等差数列)】
for i in range(5):
rnd = random.randrange(10)
print(rnd)
# 出力例:
# 8
# 3
# 2
# 1
# 7
# random()【一様分布】
for i in range(5):
rnd = random.random()
print(rnd)
# 出力例:
# 0.409240761463217
# 0.1869568160790639
# 0.5550096213832235
# 0.4911721941668322
# 0.24567783064047377
# uniform(a, b)【一様分布 (範囲指定)】
for i in range(5):
rnd = random.uniform(10, 20)
print(rnd)
# 出力例:
# 13.947031207983711
# 16.04608572314917
# 10.279244047672474
# 14.887712010294461
# 17.98819298549841
シーケンス操作関数
import random
# choice(seq)【要素選択】
for i in range(3):
num = random.choice([3, 5, 7, 11, 13, 17])
print(num)
# 出力例:
# 17
# 3
# 7
for i in range(3):
char = random.choice('abcxyz')
print(char)
# 出力例:
# b
# a
# y
population = ['aaa', 'bbb', 'ccc', 'AAA', 'BBB', 'CCC']
for i in range(3):
word = random.choice(population)
print(word)
# 出力例:
# CCC
# aaa
# ccc
# choices(population, weights=None, *, cum_weights=None, k=1)【複数要素選択(重複あり)】
population = ['aaa', 'bbb', 'ccc', 'AAA', 'BBB', 'CCC']
seq = random.choices(population, [10, 10, 10, 1, 1, 1], k=6)
print(seq)
# 出力例:['bbb', 'ccc', 'aaa', 'aaa', 'aaa', 'BBB']
seq = random.choices(population, [1, 1, 1, 10, 10, 10 ], k=6)
print(seq)
# 出力例:['BBB', 'AAA', 'CCC', 'BBB', 'CCC', 'AAA']
seq = random.choices(population, cum_weights=[1, 2, 3, 13, 23, 33], k=6)
print(seq)
# 出力例:['BBB', 'BBB', 'CCC', 'CCC', 'AAA', 'AAA']
# shuffle(x[, random])【シャッフル (インプレース)】
x = ['aaa', 'bbb', 'ccc', 'AAA', 'BBB', 'CCC']
random.shuffle(x)
print(x)
# 出力例:['aaa', 'ccc', 'bbb', 'AAA', 'BBB', 'CCC']
# sample(population, k, *, counts=None)【複数要素選択(重複なし)】
population = ['aaa', 'bbb', 'ccc', 'AAA', 'BBB', 'CCC']
seq = random.sample(population, 6)
print(seq)
# 出力例:['CCC', 'BBB', 'aaa', 'bbb', 'AAA', 'ccc']
seq = random.sample(population, 9, counts=[1, 1, 1, 2, 2, 2])
print(seq)
# 出力例:['ccc', 'aaa', 'CCC', 'BBB', 'bbb', 'BBB', 'CCC', 'AAA', 'AAA']
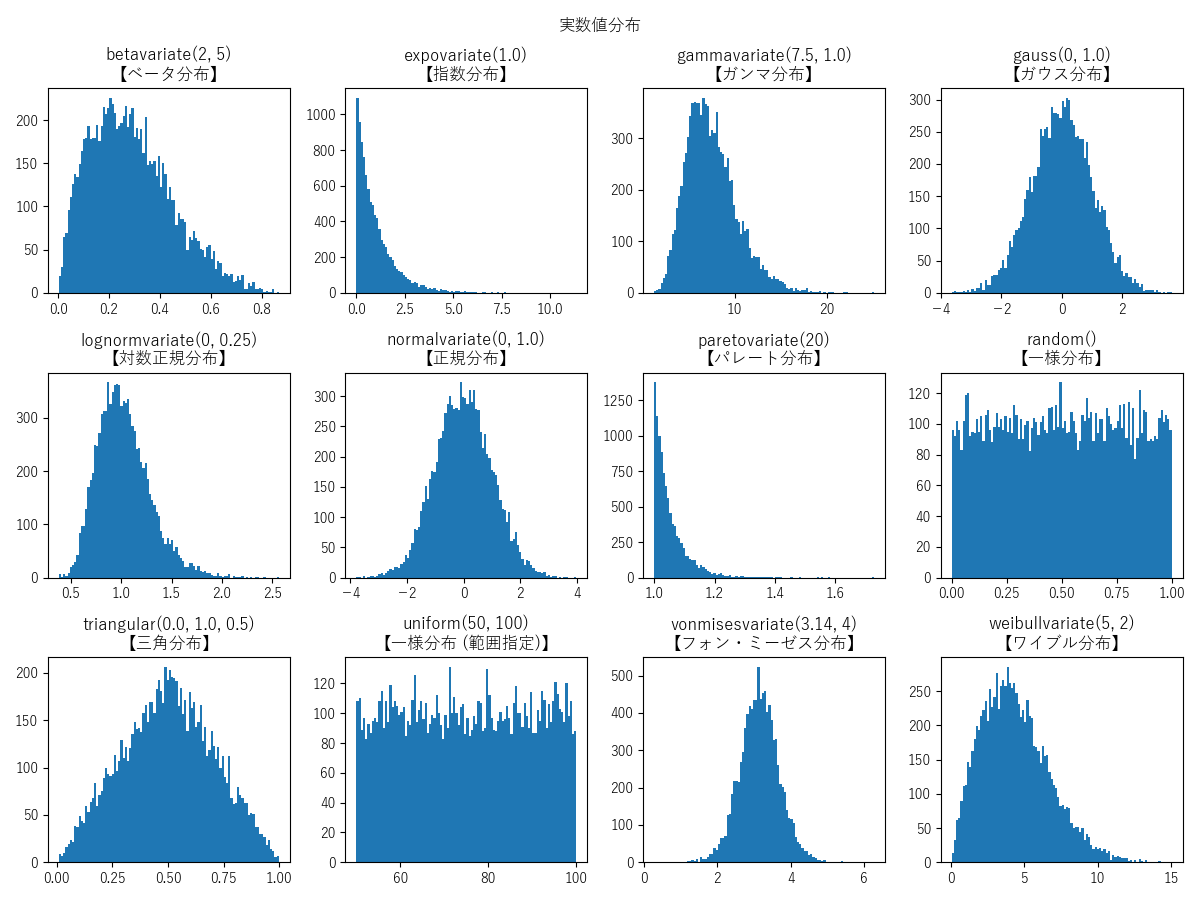
実数値分布関数
外部ライブラリの matplotlib【グラフ描画ライブラリ】使用
import random
import matplotlib.pyplot as plt
# 初期設定
plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['font.sans-serif'] =\
['Yu Gothic', 'Hiragino Maru Gothic Pro', 'Noto Sans CJK JP']
fig, axs = plt.subplots(
3, 4,
figsize=(12, 9),
tight_layout=True,
)
plt.suptitle('実数値分布')
# betavariate()【ベータ分布】
alpha = 2
beta = 5
data = [random.betavariate(alpha, beta) for i in range(10000)]
axs[0, 0].hist(data, bins=100)
axs[0, 0].set_title(f'betavariate({alpha}, {beta})\n【ベータ分布】')
# expovariate()【指数分布】
lambd = 1.0
data = [random.expovariate(lambd) for i in range(10000)]
axs[0, 1].hist(data, bins=100)
axs[0, 1].set_title(f'expovariate({lambd})\n【指数分布】')
# gammavariate()【ガンマ分布】
alpha = 7.5
beta = 1.0
data = [random.gammavariate(alpha, beta) for i in range(10000)]
axs[0, 2].hist(data, bins=100)
axs[0, 2].set_title(f'gammavariate({alpha}, {beta})\n【ガンマ分布】')
# gauss()【ガウス分布】
mu = 0
sigma = 1.0
data = [random.gauss(mu, sigma) for i in range(10000)]
axs[0, 3].hist(data, bins=100)
axs[0, 3].set_title(f'gauss({mu}, {sigma})\n【ガウス分布】')
# lognormvariate()【対数正規分布】
mu = 0
sigma = 0.25
data = [random.lognormvariate(mu, sigma) for i in range(10000)]
axs[1, 0].hist(data, bins=100)
axs[1, 0].set_title(f'lognormvariate({mu}, {sigma})\n【対数正規分布】')
# normalvariate()【正規分布】
mu = 0
sigma = 1.0
data = [random.normalvariate(mu, sigma) for i in range(10000)]
axs[1, 1].hist(data, bins=100)
axs[1, 1].set_title(f'normalvariate({mu}, {sigma})\n【正規分布】')
# paretovariate()【パレート分布】
alpha = 20
data = [random.paretovariate(alpha) for i in range(10000)]
axs[1, 2].hist(data, bins=100)
axs[1, 2].set_title(f'paretovariate({alpha})\n【パレート分布】')
# random()【一様分布】
data = [random.random() for i in range(10000)]
axs[1, 3].hist(data, bins=100)
axs[1, 3].set_title('random()\n【一様分布】')
# triangular()【三角分布】
low = 0.0
high = 1.0
mode = 0.5
data = [random.triangular(low, high, mode) for i in range(10000)]
axs[2, 0].hist(data, bins=100)
axs[2, 0].set_title(f'triangular({low}, {high}, {mode})\n【三角分布】')
# uniform()【一様分布 (範囲指定)】
a = 50
b = 100
data = [random.uniform(a, b) for i in range(10000)]
axs[2, 1].hist(data, bins=100)
axs[2, 1].set_title(f'uniform({a}, {b})\n【一様分布 (範囲指定)】')
# vonmisesvariate()【フォン・ミーゼス分布】
mu = math.pi
kappa = 4
data = [random.vonmisesvariate(mu, kappa) for i in range(10000)]
axs[2, 2].hist(data, bins=100)
axs[2, 2].set_title(f'vonmisesvariate({mu:1.3}, {kappa})\n【フォン・ミーゼス分布】')
# weibullvariate()【ワイブル分布】
alpha = 5
beta = 2
data = [random.weibullvariate(alpha, beta) for i in range(10000)]
axs[2, 3].hist(data, bins=100)
axs[2, 3].set_title(f'weibullvariate({alpha}, {beta})\n【ワイブル分布】')
# 表示
plt.show()